SKILLFLOW: Benchmarking Lifelong Skill Discovery and Evolution for Autonomous Agents
Why SkillFlow
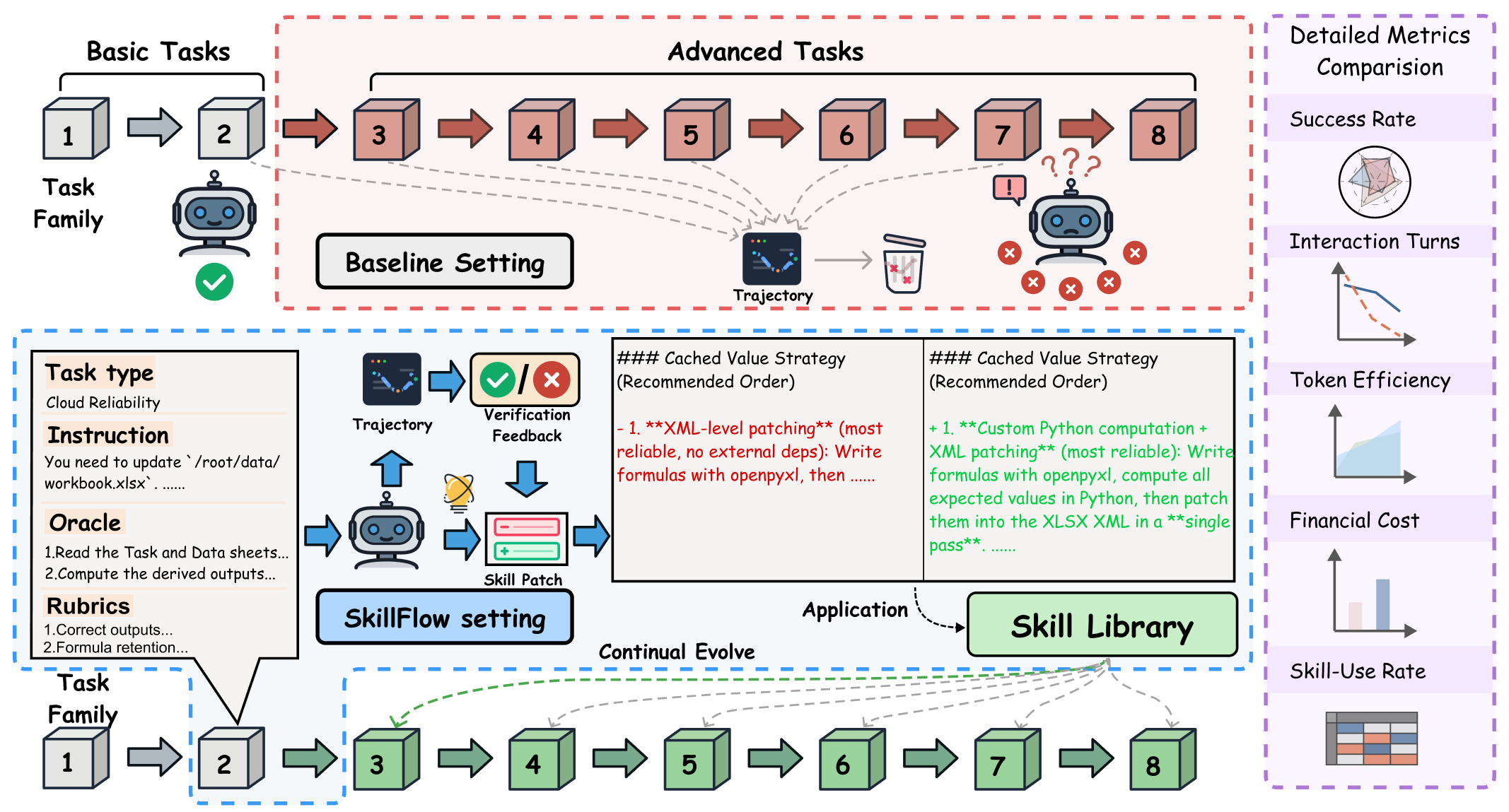
Most agent benchmarks stop at asking whether a model can consume a provided skill. SKILLFLOW asks a harder and more realistic question: can an agent solve a task, distill the lesson into a reusable skill artifact, repair that skill after later failures, and carry a better library forward through a family of related tasks?
Abstract
As the capability frontier of autonomous agents continues to expand, they are increasingly able to complete specialized tasks through plug-and-play external skills. Yet current benchmarks mostly test whether models can use provided skills, leaving open whether they can discover skills from experience, repair them after failure, and maintain a coherent library over time.
SKILLFLOW is a benchmark of 166 tasks across 20 workflow families in which task construction follows a shared Domain-Agnostic Execution Flow (DAEF). Under the proposed Agentic Lifelong Learning protocol, agents begin without skills, solve tasks sequentially within each family, externalize lessons through trajectory- and rubric-driven skill patches, and carry the updated library forward.
Experiments reveal selective rather than universal gains. Claude Opus 4.6 improves from 62.65% to 71.08% task completion, but high skill usage does not automatically mean high utility: Kimi K2.5 gains only +0.60 despite 66.87% skill usage, while both Qwen-Coder-Next and Qwen3-Coder-480B regress under skill evolution.
Benchmark Visuals
These figures summarize the dual-agent construction pipeline, the five-domain benchmark taxonomy, and the DAEF correspondences that let SKILLFLOW study procedural transfer beyond surface-level domain overlap.
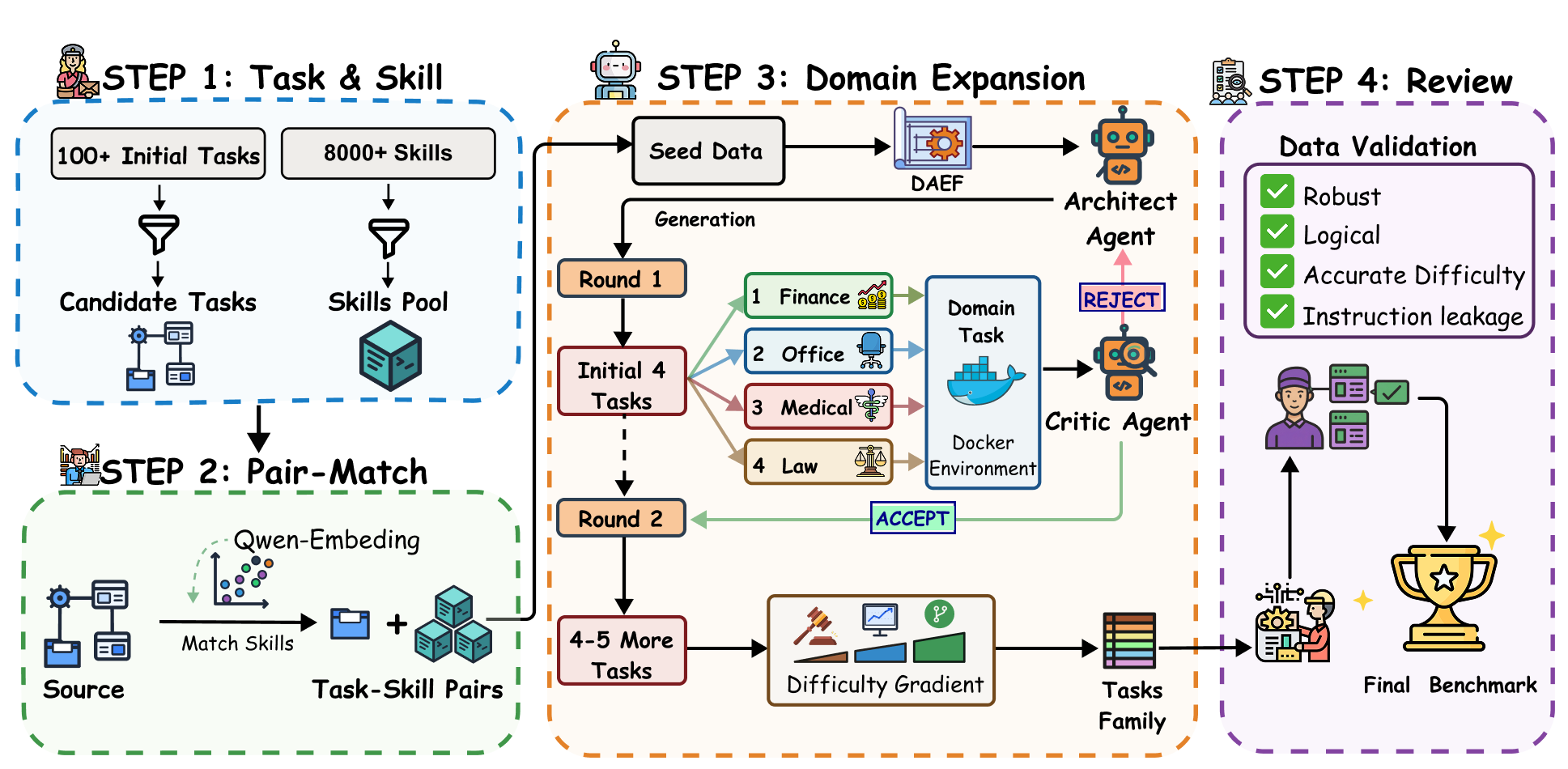
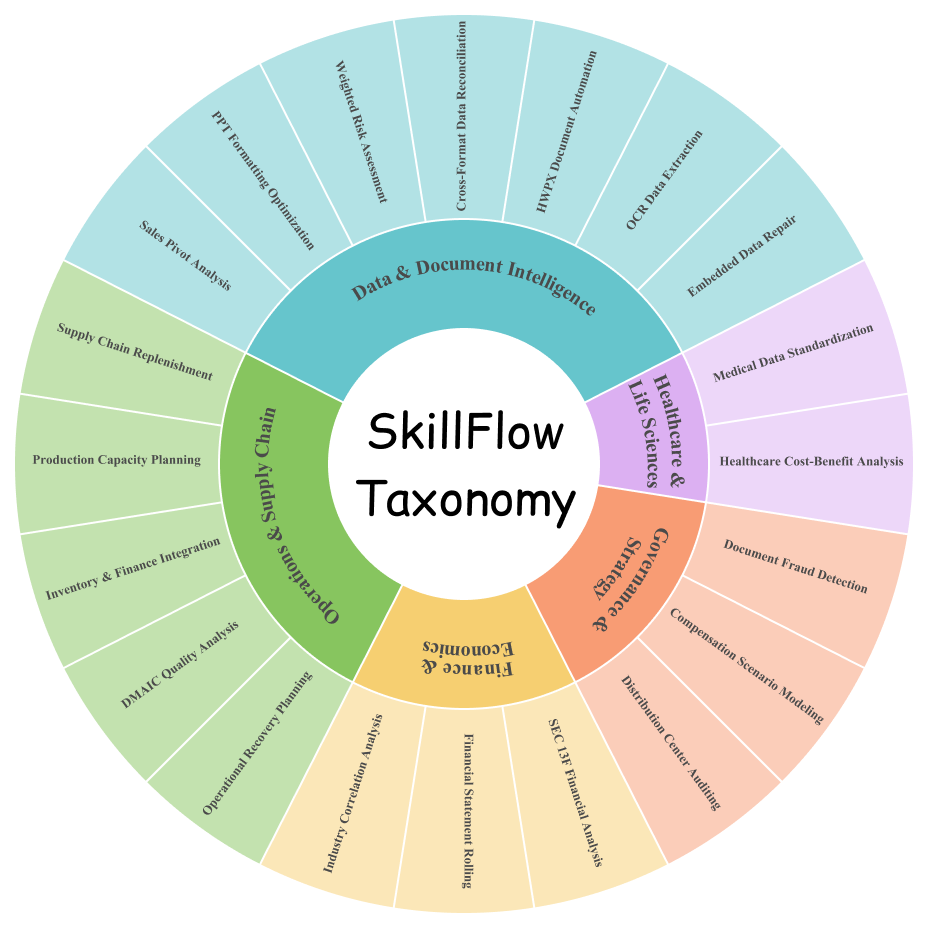
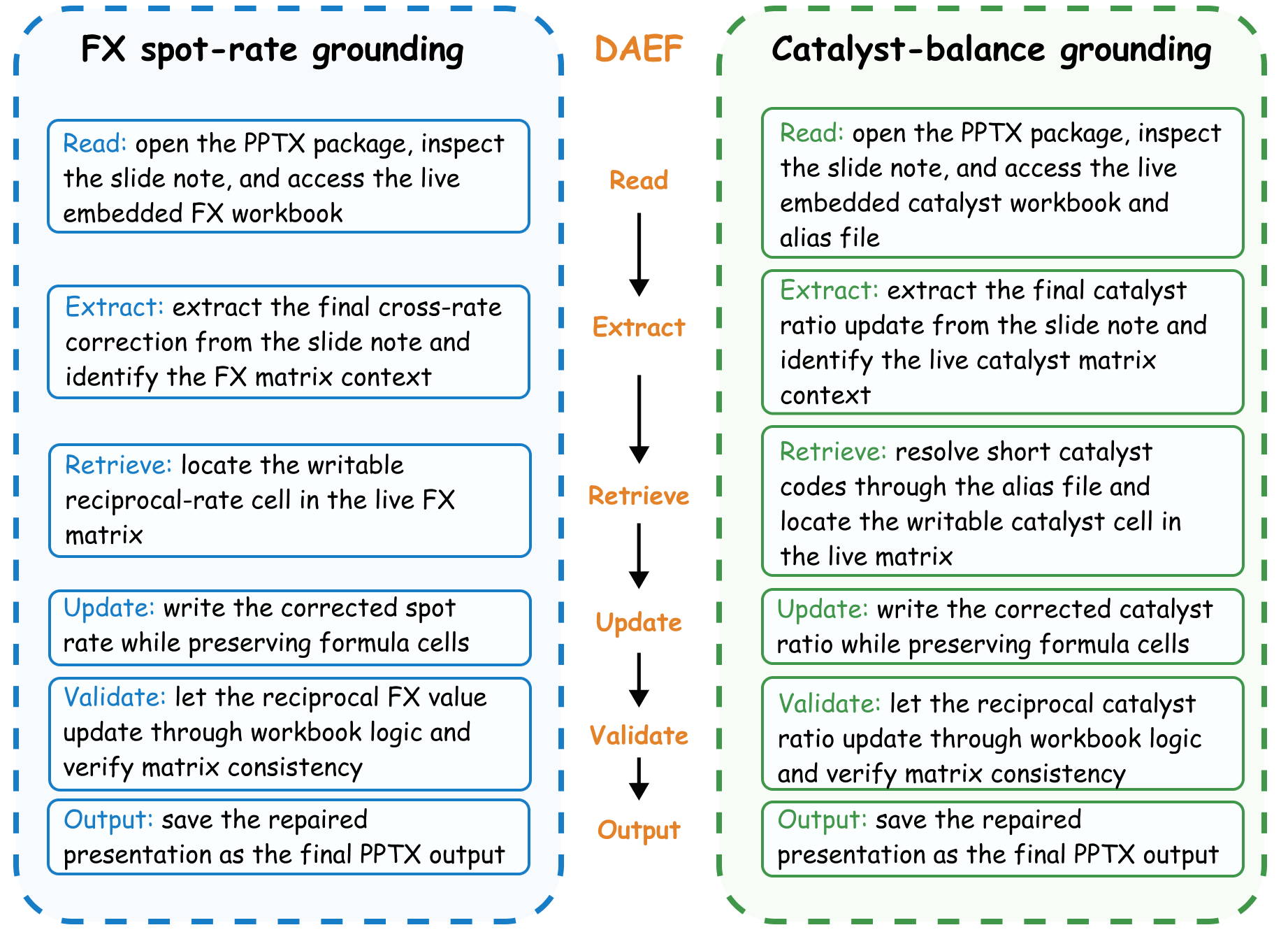
What the Benchmark Tracks
SKILLFLOW reports both outcome and process: whether agents solve tasks, how efficiently they do so, and how their skill libraries evolve under sequential evaluation.
Task Success Rate
The primary score is whether the final output satisfies the verifier, giving a clean measure of end-to-end task completion.
Efficiency
SKILLFLOW also reports interaction turns, monetary cost, and output tokens to show whether gains come with better or worse execution efficiency.
Skill Generation and Reuse
Each setting tracks how many skills survive in the final family-local library and how often previously written skills are actually reused later.
Family-Local Transfer
Tasks follow a fixed order within each workflow family, making every improvement or regression traceable to how well lessons move forward under a shared DAEF.
Main Experimental Results
Table 1 reports benchmark-level averages for 11 model variants across Claude Code, Codex CLI, Qwen Coder, and Kimi CLI. The clearest positive case is Claude Opus 4.6, which improves from 62.65% to 71.08% completion under lifelong skill evolution.
| Agent | Model | Vanilla | Skills Evolve | Δ | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| %comp. | Turns | Cost | Out Tok. | %comp. | Turns | Cost | Out Tok. | #Skills | %use | %Comp. | Turns | Cost | Tok. | ||
| Claude Code | Claude Sonnet 4.5 | 49.4 | 25.04 | 0.293 | 1.07 | 55.42 | 24.88 | 0.246 | 0.85 | 2.55 | 72.89 | ▲ 6.02 | ▼ 0.16 | ▼ 16.04% | ▼ 20.56% |
| Claude Opus 4.5 | 58.43 | 18.83 | 0.571 | 1.5 | 60.84 | 18.31 | 0.384 | 1.4 | 1.5 | 60.84 | ▲ 2.41 | ▼ 0.52 | ▼ 32.87% | ▼ 6.67% | |
| Claude Sonnet 4.6 | 56.63 | 17.48 | 0.168 | 1.23 | 56.63 | 17.42 | 0.245 | 1.59 | 2.55 | 53.01 | • 0.00 | ▼ 0.06 | ▲ 45.83% | ▲ 29.27% | |
| Claude Opus 4.6 | 62.65 | 17.34 | 0.665 | 3.00 | 71.08 | 19.00 | 0.615 | 2.39 | 1.05 | 45.78 | ▲ 8.43 | ▲ 1.66 | ▼ 7.52% | ▼ 20.33% | |
| MiniMax M2.5 | 28.31 | 35.22 | 0.010 | 0.44 | 34.94 | 34.01 | 0.010 | 0.54 | 2.50 | 32.53 | ▲ 6.63 | ▼ 1.21 | • 0% | ▲ 22.73% | |
| MiniMax M2.7 | 37.35 | 25.44 | 0.012 | 0.5 | 36.75 | 27.42 | 0.017 | 0.96 | 4.65 | 51.2 | ▼ 0.60 | ▲ 1.98 | ▲ 41.67% | ▲ 92% | |
| Codex CLI | GPT 5.4 | 33.13 | 23.89 | 0.41 | 4.05 | 36.75 | 24.17 | 0.459 | 4.43 | 1.05 | 81.33 | ▲ 3.62 | ▲ 0.28 | ▲ 11.95% | ▲ 9.38% |
| GPT 5.3 Codex | 52.41 | 17.74 | 0.492 | 6.8 | 46.39 | 17.14 | 0.434 | 6.82 | 1.1 | 84.94 | ▼ 6.02 | ▼ 0.60 | ▼ 11.79% | ▲ 0.29% | |
| Qwen Coder | Qwen-Coder-Next | 45.18 | 18.64 | 0.103 | 9.74 | 44.58 | 19.91 | 0.113 | 10.69 | 5.45 | 12.05 | ▼ 0.60 | ▲ 1.27 | ▲ 9.71% | ▲ 9.75% |
| Qwen3-Coder-480B | 24.7 | 26.22 | 0.189 | 12.58 | 24.1 | 28.8 | 0.199 | 12.12 | 5.2 | 66.87 | ▼ 0.60 | ▲ 2.58 | ▲ 5.29% | ▼ 3.66% | |
| Kimi CLI | Kimi K2.5 | 55.42 | 12.62 | 0.103 | 7.31 | 56.02 | 11.51 | 0.104 | 7.10 | 1.50 | 66.87 | ▲ 0.60 | ▼ 1.11 | ▲ 0.97% | ▼ 2.87% |
Main Findings
Opus 4.6 is the clearest positive case
Claude Opus 4.6 rises from 104/166 to 118/166 solved tasks, and a history-only control reaches just 51.04%, suggesting the gain comes from structured skill externalization rather than longer context alone.
Bad skills can create downstream drift
Once an incorrect abstraction is written into the library, later tasks may inherit the same mistake, turning a local failure into a sequence-level pattern.
Compact evolving skills beat fragmented ones
The strongest libraries are built around a small number of repeatedly repaired high-utility skills, not a pile of narrowly scoped task-by-task memories.
Qwen and part of MiniMax suffer from skill inflation
Several weaker settings keep adding overlapping skills almost monotonically with task index, yet still fail to convert that growth into benchmark-level gains.
Codex stays compact, but compactness is not enough
Codex often consolidates nearby variants into a shared evolving core skill, but that organizational strength alone does not match the strongest end-to-end gains.
Repairing bad skills is harder than writing them
Most models can write something after a task, but the real gap is whether they can recognize a flawed skill, repair it, and obtain better behavior on later tasks.
Benchmark Design
- DAEF-structured workflow families: tasks are grouped by shared executable topology rather than shallow domain overlap.
- Family-local curricula: agents start with an empty library, follow a fixed within-family difficulty order, and reset the library across different workflows.
- Auditable skill patches: every update records a summary plus
upsert_filesanddelete_paths, making repair and uncontrolled growth directly inspectable. - Docker-based closed evaluation: tasks run inside controlled containerized environments, so transfer is measured under stable execution constraints instead of open-world drift.
BibTeX
@article{zhang2026skillflow,
title={SkillFlow: Benchmarking Lifelong Skill Discovery and Evolution for Autonomous Agents},
author={Zhang, Ziao and Shi, Kou and Huang, Shiting and Nie, Avery and Zeng, Yu and Zhao, Yiming and Fang, Zhen and Su, Qisheng and Qiu, Haibo and Yang, Wei and Ren, Qingnan and Zou, Shun and Huang, Wenxuan and Chen, Lin and Chen, Zehui and Zhao, Feng},
year={2026},
journal={arXiv preprint arXiv:2604.17308},
eprint={2604.17308},
archivePrefix={arXiv},
url={https://arxiv.org/abs/2604.17308}
}